 六维的个人博客
六维的个人博客若从生成方式分类,AI 视频生成包含:
- 文生视频、图生视频(Runway、Pika labs、SD + Deforum、SD + Infinite zoom、SD + AnimateDiff、Warpfusion、Stability Animation)
- 视频生视频:又分逐帧生成(SD + Mov2Mov)、关键帧+补帧(SD + Ebsynth、Rerender A Video)、动态捕捉(Deep motion、Move AI、Wonder Dynamics)、视频修复(Topaz Video AI)
- AI Avatar+语音生成:Synthesia、HeyGen AI、D-ID
- 长视频生短视频:Opus Clip
- 脚本生成+视频匹配:Invideo AI
- 剧情生成:Showrunner AI
若从产品阶段和可用维度分类:

下面将按照上图维度进行产品介绍。
本节产品适合专业创作者进行电影、MV、宣传片等艺术作品中,有操作简单的 Pika labs、Runway,也有基于 Stable Diffusion 能力延伸的插件。这些产品能够被学习并掌握,因此本节内容除了产品介绍,还会有实践教学的部分。
1. Runway
该产品年初在互联网爆火,泥塑人物的风格化视频想必大家都不陌生:

Runway 由一家总部位于旧金山的 AI 创业公司制作,其在 2023 年初推出的 Gen-2 代表了当前 AI 视频领域最前沿的模型。能够通过文字、图片等方式生成 4s 左右的视频。Runway 致力于专业视频剪辑领域的 AI 体验,同时也在扩展图片 AI 领域的能力。目前 Runway 支持在网页、iOS 访问,网页端目前支持 125 积分的免费试用额度(可生成约 105s 视频),iOS 则有 200 多,两端额度貌似并不同步,想要更多试用次数的朋友可以下载 iOS 版本。
详细介绍:
AI短视频神器Gen-2开放测试!靠打字做短视频的时代来了?
大家好,这里是和你们一起探索 AI 的花生。
阅读文章 >
①Gen-1 和 Gen-2 的区别和使用方法
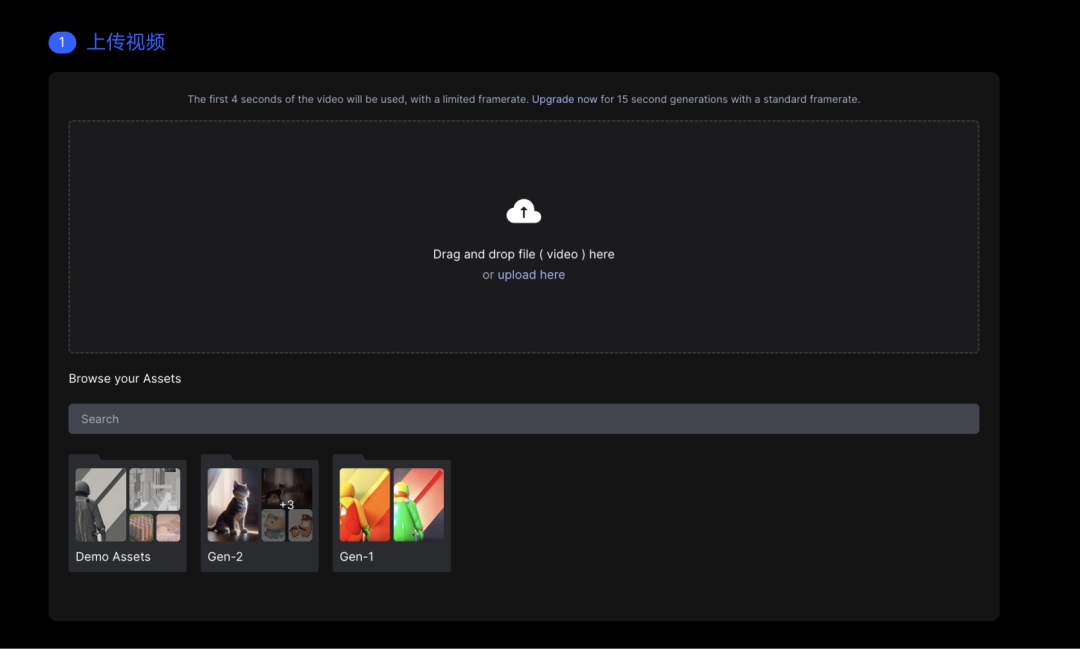
Gen-1
Gen-1 的主要能力有:视频生视频(Video 2 Video)、视频风格化、故事版(将实体模型风格化)、遮罩等其中,仅支持视频生视频是 Gen-1 和 Gen-2 的最大差异。
Gen-1 使用流程:
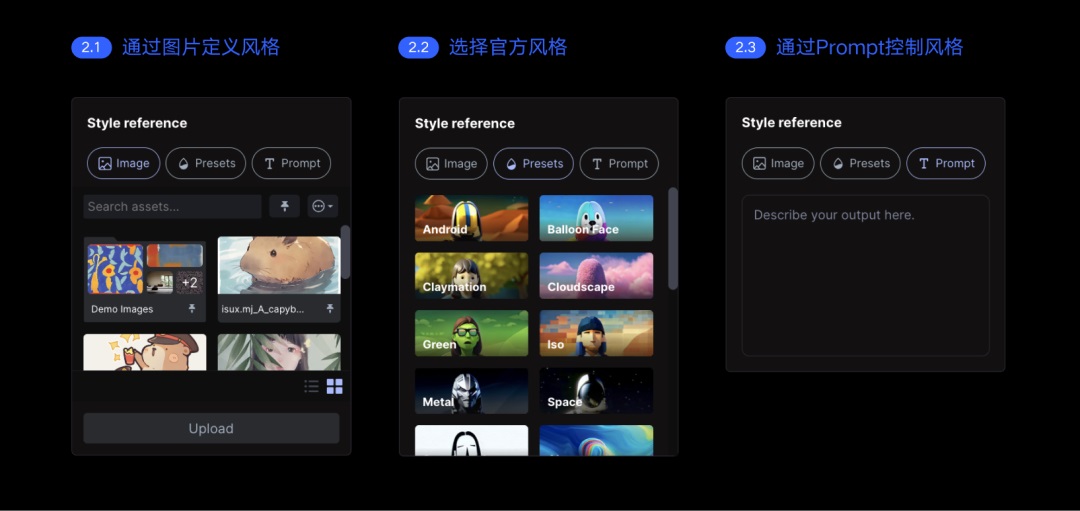
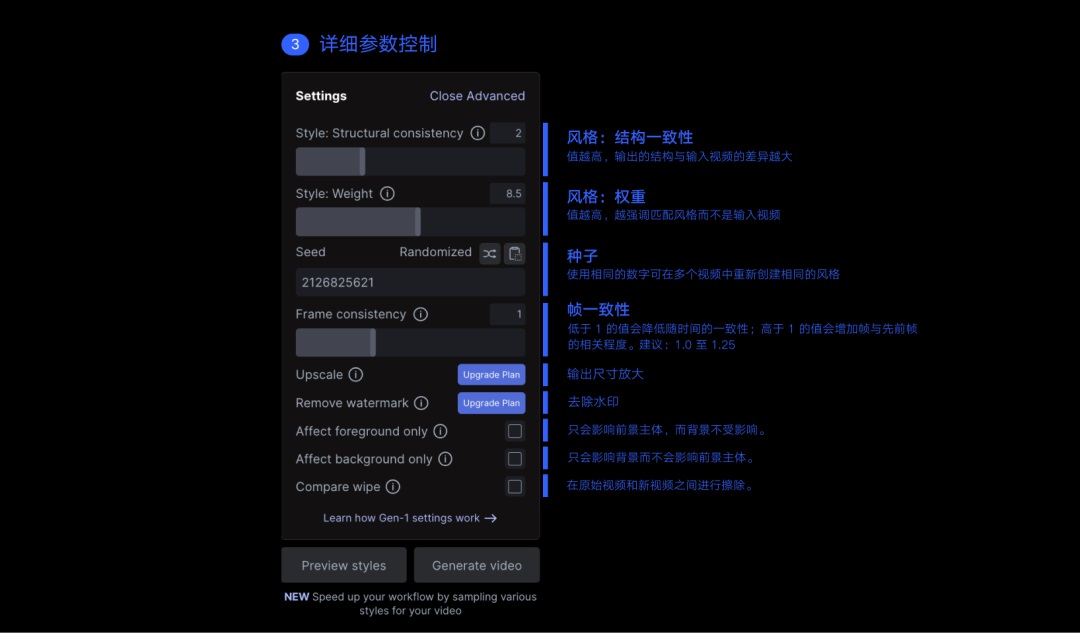
Gen-1 能力介绍:
Runway!AI技术+视频制作的新一代视频内容生成工具
大家好,这里是和你们聊设计的花生~ 之前和大家聊过不少 AI 图像生成工具,有的可以根据文本生成图像,有的则是将 AI 技术运用到图像处理中,让扣除背景、消除画面元素成为非常轻松快速的事情,大大提升了设计师的工作效率。
阅读文章 >
Gen-1 参数设置: https://help.runwayml.com/hc/en-us/articles/15161225169171
也可以看这个视频学习 Gen-1 的详细设置方式: https://youtu.be/I4OeYcYf0Sc
Gen-2
Gen-2 的主要能力有:文生视频(Text 2 Video )、Prompt+图像生成视频(Text + Image to Video )也支持无 Prompt 直接图片转视频(Image to Video),通常图生视频时,更推荐使用 Image to Video。想要使用 Gen-2,点击顶部的 Start with Image、Start with Text 即可。
Text to Video 时,建议优先使用右下角的“Free Preview”免费生成多组图片,然后从中选择一张进行视频生成,这样可以节约 credits。
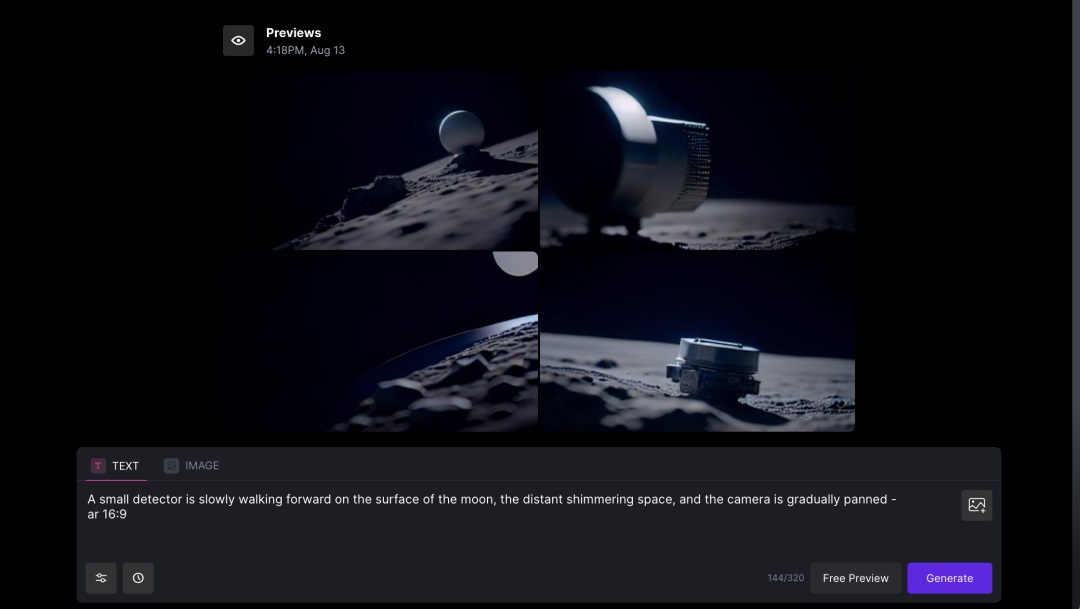
Runway 最近的更新中,支持将 4s 的视频延长,每次延长需要消耗 20credits,从 Runway 的付费情况来看,有点用不起。
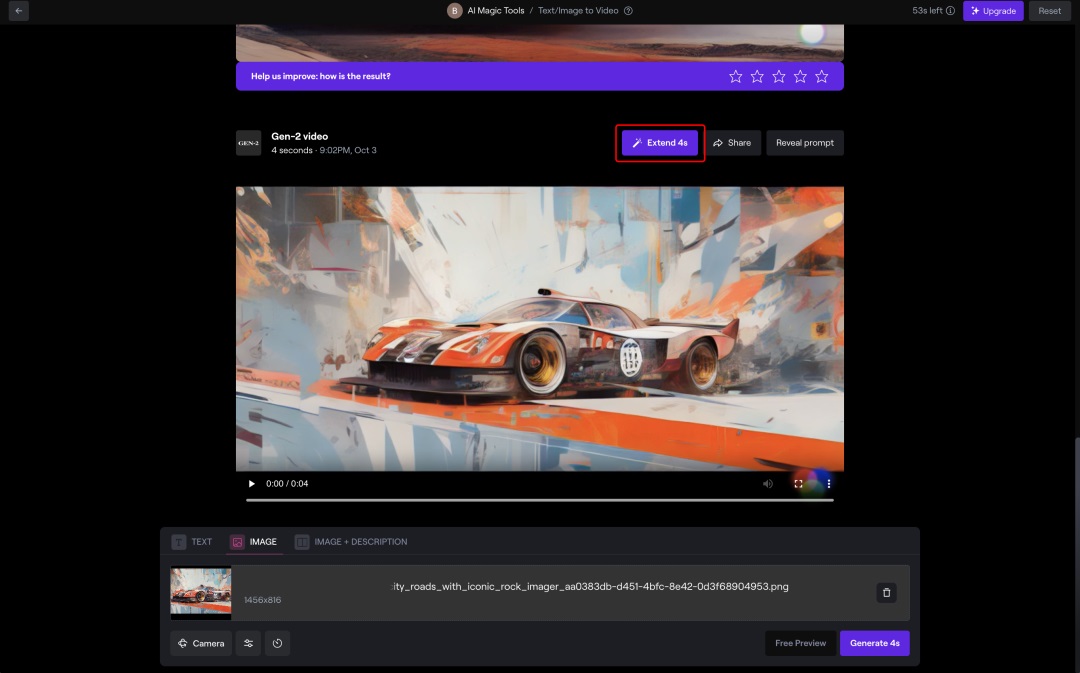
②Motion 控制
9 月的更新中,runway 支持了 1-10 级的 motion slider 调节,默认幅度为 5
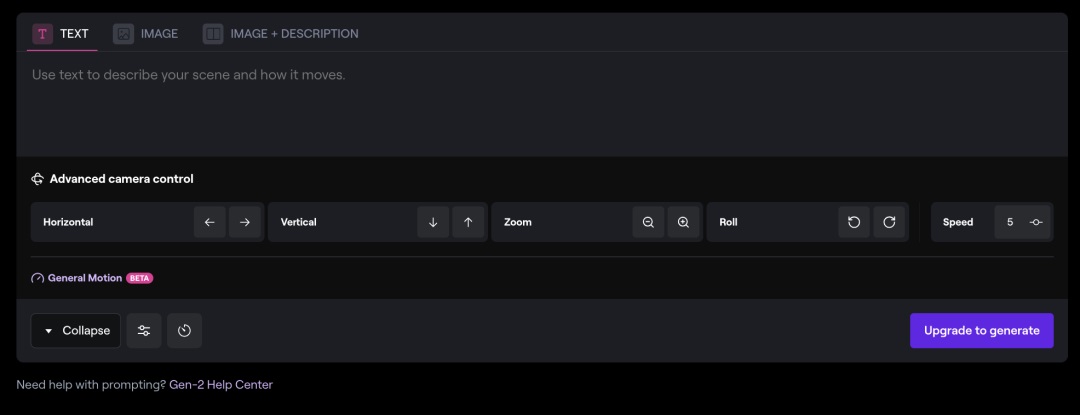
③运镜能力
同时支持了水平、垂直、空间和旋转,并且支持调节运动速度
④30 多项图片、视频处理能力
除了最基础的图像、视频生成能力,Runway 还提供 30 多项图片、视频处理能力,包含:Inpainting 视频修复;Motion Tracking 视频主体跟随运动;Remove Any Background 删除视频元素/背景;3D Texture 生成 3D 纹理等。
推荐这个教程,基本功能都有介绍一遍:https://www.youtube.com/watch?v=Yj73NRmeSZM
Watch
近期 Runway 控制台上线了 Watch 模块,可以查看官方精选的创意案例。
Pika labs
该产品目前推出了 Beta 版本,支持免费、不限次数地文生视频、图生视频,和 Runway 一样, 生成的视频会带上官方水印。Pika labs 很少披露其产品、技术的详细情况,官网也没有花精力好好做,在国内外的影响力都没有 Runway 大,但其生成效果足以站上 AI 视频的牌桌。
Pika!又一个AI短视频生成神器,免费使用!
大家好,这里是和你们一起探索 AI 的花生~ 之前为大家推荐过一款知名的 AI 视频生成工具 Runway,它的 Gen-2 模型可以直接根据文本生成视频,效果稳定。
阅读文章 >
优秀案例:
近期 x 上一个创作者发布的庆祝星球大战 100 周年的短片做的非常成功:
这位导演用 Pika labs 产出的视频都非常高质量:By:Matan Cohen-Grumi
使用方法
- 目前在 Discord 试用 Beta 版本: http://discord.gg/pika
- 选择 generate-x 开头的频道或者建立 pika labs 私信
- “/create” 输入 prompt 即可完成文生视频

输入 prompt 后,点击“增加 1”可添加 image 进行文+图生视频


如果你想仅输入图片,不输入 Prompt 来生成视频,可以使用/animate 命令
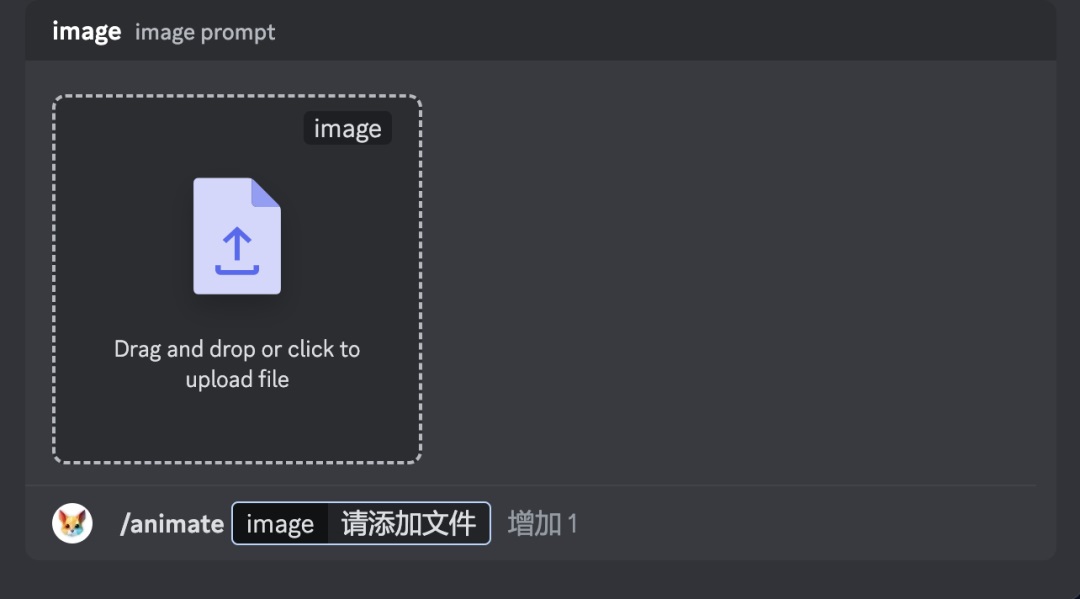
此外,🔄可以帮助用户快速进行多次生成,🔀则可以方便的可控参数能基本满足需求。
文本、图像加密
9 月,pika 更新了新能力加密信息。使用命令/encrypt_text,可以将最多 20 个字符的文本“加密”到给定的视频输出中。
By:Matan Cohen-Grumi
而/encrypt_image,则可以实现输入 logo image,生成图像动画中含有 logo 的效果:
By:Matan Cohen-Grumi
值得一提的是,最好将 logo 文件处理为黑底白图,否则 pika labs 可能无法识别。
使用/encrypt_image 命令时,除了输入一张 logo image,还可以选择性增加一张垫图,垫图会对视频整体风格、内容产生影响。
③控制参数介绍

在 Prompt-tutorial 频道,有很多值得一看的教学视频,而在 showcase 频道和官方 twitter 中可以看到许多优秀案例。
Pika labs 和 Runway Gen-2 效果对比
A.生成效果对比
Runway VS Pika(8 月版)
B.运镜控制效果对比
Runway VS Pika(By:瑶酱)
C.对比小结
1)可控性
经过 9 月 runway 在控制器上的大更新,目前两者的控制能力不相上下。细节上,Runway 在 motion 控制效果上略胜一筹,而 Pika labs 在图形、文字的显示上更快一步。
2)连贯性
旧版 Pika labs 在帧的连贯性上差一些,但近期官方将帧数改为 24 帧后效果提升显著,和 Runway 没有较大差异。
3)生成效果
在尝试并看过很多案例发现,Runway 生成效果通常比 Pika labs 的生成效果动作幅度更大更夸张,这也是导致 Runway 生成的许多效果有明显瑕疵的原因。在一些场景下,我个人更喜欢 Pika labs 在细节上呈现的高水平动态效果,能够保证主体物没有明显变形和风格化。但 Pika labs 总是呈现物体动而背景静止的效果,Runway 的大幅度变化有时能带来更多意想不到的效果。
我们也可以通过 Prompt 或者在 pika 中增加镜头变换(对,不是 motion,前面说过 pika 在 motion 上控制效果不显著)来增加运动幅度。
4)价格
Runway 最低档的充值每月 15 刀,而 Pika labs 目前完全免费。总的来说,目前 runway 和 pika labs 都需要反复测试视频生成效果,并通过后期的剪辑处理形成可用的视频内容。由于 Runway 尝试次数实在有限,我个人还是喜欢使用 Pika labs 更多一点。
更多效果对比可查看: https://youtu.be/CB_Y-5yaQ-M
2. Stable Diffusion +
这应该是目前最具备可控性的一种 AI 视频生产方式了,同时也具备着一定上手成本。最早是看到海辛的分享,通过学习 Nenly 同学(B 站)的保姆级教程(从安装到使用包教包会)和具体工具教程一步步理清思路并进行了案例实践。下面对用到的具体插件进行详细介绍,由于过程确实复杂,理解起来需要一定门槛,对 SD 不感兴趣的同学可以跳过这一段,继续看其他产品案例就好。
①准备工作
- 安装并掌握简单的 Stable Diffusion 基础,确保 FFmpeg 被安装(这将保证后续介绍的扩展能够生成视频预览)。
- 准备好图片、视频素材这里推荐新手选取单人、简单场景、简单动作变化的视频,会更容易出效果(我选择的蜘蛛侠人物、动作变化多,前景色和背景色区别小,在生成时容易踩坑);另外需控制视频的长度,否则生成时间会过长。
A. Mov2Mov 逐帧重绘
产品介绍:
最早火起来的 SD 动画插件之一,mov2mov 的原理是提取视频的帧,并将每一帧按照用户设置的模型和 prompt 重新绘制,然后将生成的视频组合成视频并输出。对比 SD 自带的批量图生图,更推荐 mov2mov 插件。直接通过提示词控制、生成最终视频,省去了用其他视频产品将多张图片转成视频的过程。但比起 Deforum,Mov2Mov 的能力比较单一,生成视频的闪烁也较大,胜在操作十分简单。
实践过程:
1)用 SD 的 isnet_Pro 插件将视频转成帧
2)选取其中一帧,尝试不同模型、Lora、Prompt 下的效果,最终我选取了 Counterfeit 的二次元风格模型和其对应的 VAE,该模型绘制效果偏复古漫画风格。

提示词微调的情况下,不同大模型绘制出的效果
3)下载 mov2mov 插件,并使用视频转视频,等待一段较长的时间后就可以在 output 文件夹内看到视频效果啦。为了加快生成速度,我将视频等比缩小成了 960*540 尺寸进行生成(此举会对风格化效果有所影响:与原图 1:1 输出时,风格化效果偏 2.5D,1:0.5 输出时,效果偏 2D,不过这不影响我们了解 mov2mov 的效果)
最终效果演示推荐 Nenly 同学的 mov2mov 教程:https://www.bilibili.com/video/BV1Su411b7Nm/
B. EbSynth 自动补帧
产品介绍:
EbSynth 是一款轻量的图片处理软件,早在 19 年就公开发布。AI 绘画火爆后,许多创作者使用 EbSynth 自动生成关键帧之间的过渡帧,从而实现静态图像到动画的转换。相较 mov2mov 逐帧转绘的方法,EbSynth 可大幅降低动画制作的时间。
官网下载客户端: https://ebsynth.com/
实践过程:
通过手动抽取关键帧,随后进行关键帧重绘,再使用 EbSynth 桌面端软件补帧并使用 AE 图片序列转视频:
1.先使用 SD 的 isnet_Pro 插件将视频转成帧
2.人工选取一些动作有明显变化的关键帧,放在 SD 图生图中逐张进行风格化
3.提取视频的蒙版,将视频导出 Alpha Channel 序列,方便后续导入 EbSynth Mask 类目。开启“蒙版绘制”将人物和背景分开绘制,以达到减少“视频闪烁”的效果。
这一步有多种方法可以解决:
a.在 AE 中蒙版绘制,该操作需要原视频背景比较干净,和主体部分有明显的色彩差异。操作教程在这里: https://www.youtube.com/watch?v=81L1y3LwX6Y
b.如果你付费了 Runway,有一种更简单的方式可以提取 Alpha Channel 序列,那就是使用自动绿幕抠像功能,在选中人物主体后,已经能够比较精准的识别每一帧中的主体信息,即使是在如下案例中,主体和背景差距很小的情况下也表现的优秀(导出的视频仍需使用 isnet_Pro 插件转成帧,保存为 Mask 文件夹)
1)打开 EbSynth 本地应用,在关键帧之间补帧,最终得到了一堆补帧后生成的图片
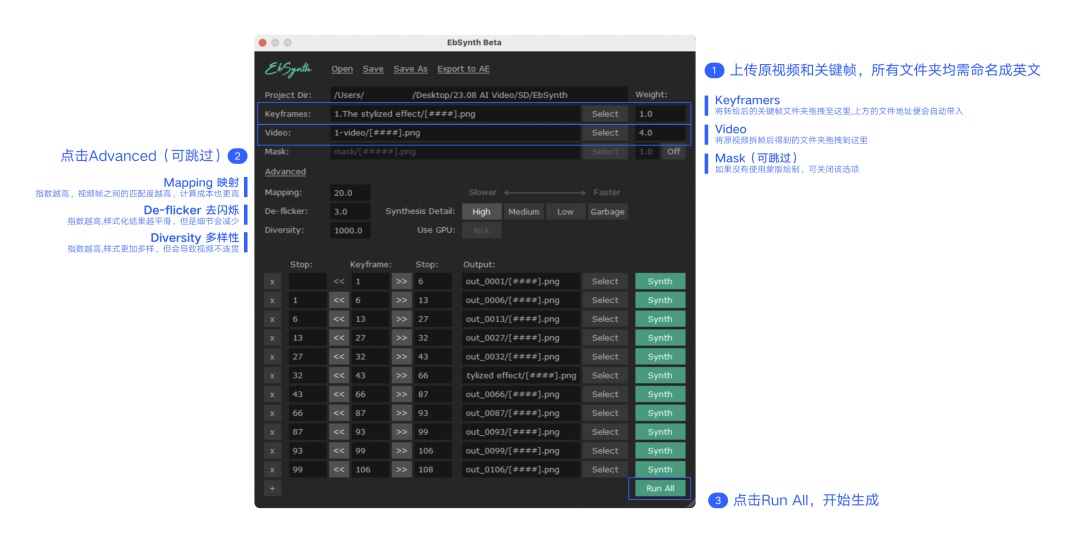
拖拽刚才生成的文件夹到 AE 中,编辑成视频并导出
EbSynth 视频生成效果 Miles 整体的动画效果不错,而 Gwen 在动作范围变化较大的时候还存在较多瑕疵,此时应该增加更多风格化关键帧,这里作为案例演示,不再深入了。另外如果在图像生成过程中增加 controlnet 控制,生成的图像效果应该能够保持更多的一致性。
( 另外 EbSynth 还有一款 SD 插件,配合安装额外工具可以最大程度的将 AI 视频生成工作流保留在 SD 中,但经过尝试不推荐使用 mac 系统的同学使用,额外工具在 mac 上的安装较为繁琐,插件存在运行 bug。使用 Windows 系统的同学可参考 Nenly 同学的教程: https://www.bilibili.com/video/BV1uX4y1H7U3
总的来说,EbSynth 可以在仅生成 1/10-1/5 风格化关键帧的同时通过补帧达到不错的视频效果。
C.Deforum 文/图生视频
产品介绍
Deforum 是一个基于 Stable Diffusion 的开源项目,可实现复杂的缩放、位移、旋转动画,并且可以同时控制多个帧间隔中的动画差异、提示词差异。可控性远远超过 Runway 和 Pika labs,生成效果也十分惊艳,缺点是控制参数较为复杂,生成时间较长,逐帧重绘方式效率低。项目地址: https://github.com/deforum-art/deforum-stable-diffusion
优秀案例
我非常喜欢的一个 Deforum 案例,使用了多段图生视频剪辑:
By Art On Tap
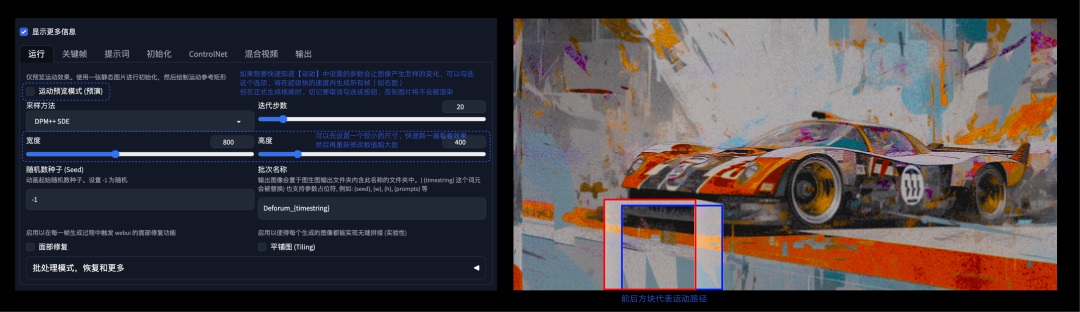
使用方法
Deforum 的设置比较复杂,需要一些耐心,重要的设置项都在下图中说明了:
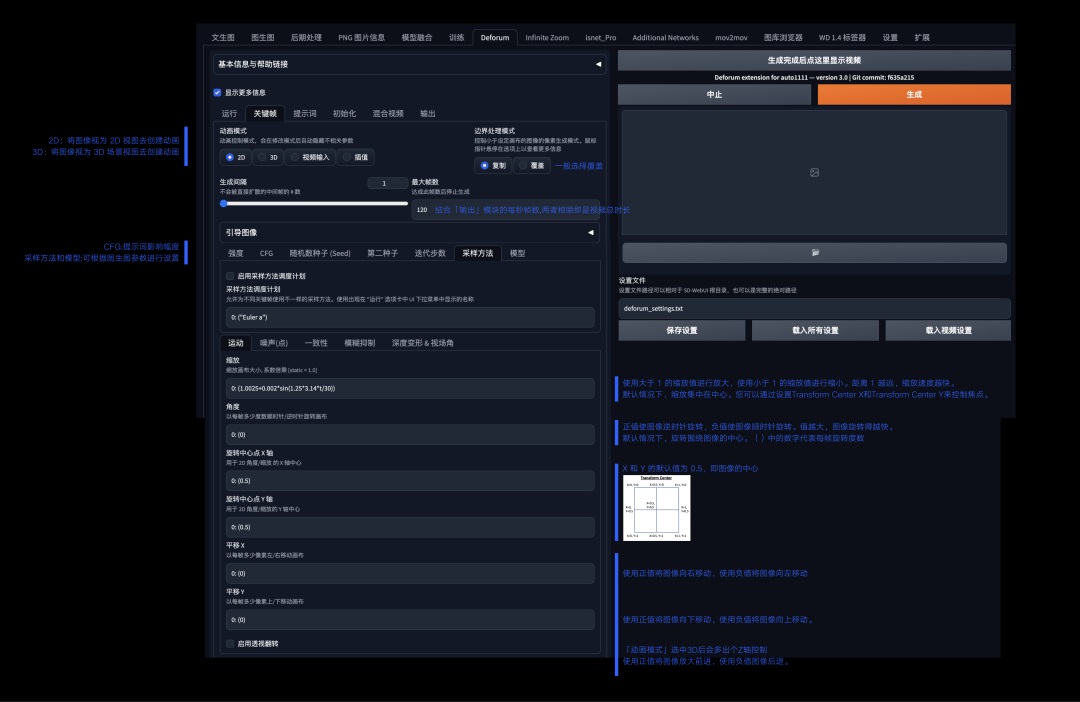
不同设置项目的差异可以看如下测试,在以下单一参数设置为 0:(0.5)时,其中旋转中心点需和角度搭配使用:
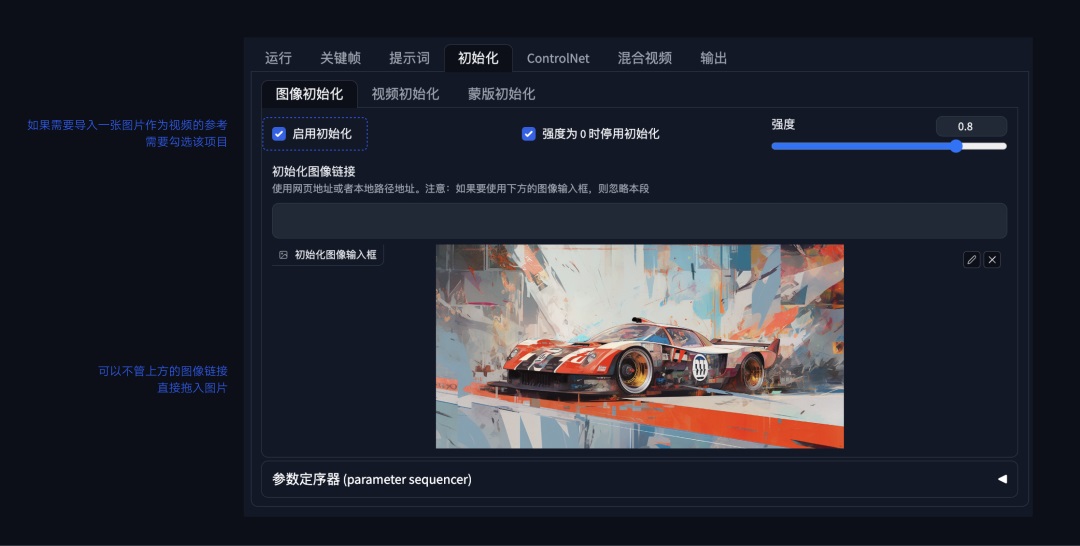
看了上面的设置,你可能会感到头痛,如果我们因为一些原因重启 SD,所有的项目都要重新设置一遍吗?这里对比其他扩展,Deforum 提供了一个非常方便的能力,点击图片生成区域下方的“保存设置”即可将此时 Deforum 扩展中的所有设置保存,点击“载入所有设置”,除了初始化图像输入框中的图片需要重新导入,其他都可以直接使用。同时每一次视频生成,Deforum 都会将运行的设置项代码保存在相应的文件夹中,方便用户回溯。

注:Deforum 采取的仍然是逐帧绘制的方式,图片尺寸过大,会导致视频生成时间太长。相应的,缩小图片尺寸,生成的细节和细节质量会降低,在对视频效果没啥把握的前期,建议等比缩小视频尺寸,生成满意的效果后再按大图生成最终视频。
实践过程
这里我选了一张在 Midjourney 中绘制的赛车图像,想要描绘赛车在赛车场上飞驰的画面。生成时主要用到了 3D 控制实现了车身偏移的效果,并且添加了镜头的缩小放大。尽管比 Mov2Mov 生成的效果更好,但 Deforum 还是没法避免闪烁,后面我将介绍另外一款产品 Topaz VideoAI 来解决这个问题。
资料推荐:
文字教程,包含详细的设置效果教学: https://stable-diffusion-art.com/deforum/
详细的视频教学 : https://www.youtube.com/watch?v=meSF8MsC2PM
更硬核的教程 ,使用 Paseq 工具更好的控制 Deforum 的复杂参数: https://www.youtube.com/watch?v=n4zj1lrbIEM
D. Infinite zoom 图片无限放大
产品介绍
Infinite zoom 可以基于原图生成高分辨率的无限缩放图像。主要思路是首先生成不同尺度的图像切片,然后通过重叠融合生成无缝的大图像,并可以不断放大浏览。该插件提供 Prompt 分段输入,分别控制整体场景和样式,近景内容,中景内容和远景内容,方便更细致地控制无限缩放图像的场景与细节。Github: https://github.com/v8hid/infinite-zoom-automatic1111-webui
使用方法
比起 Deforum,Infinite zoom 的设置比较简单,生成图片张数和视频秒数相同。
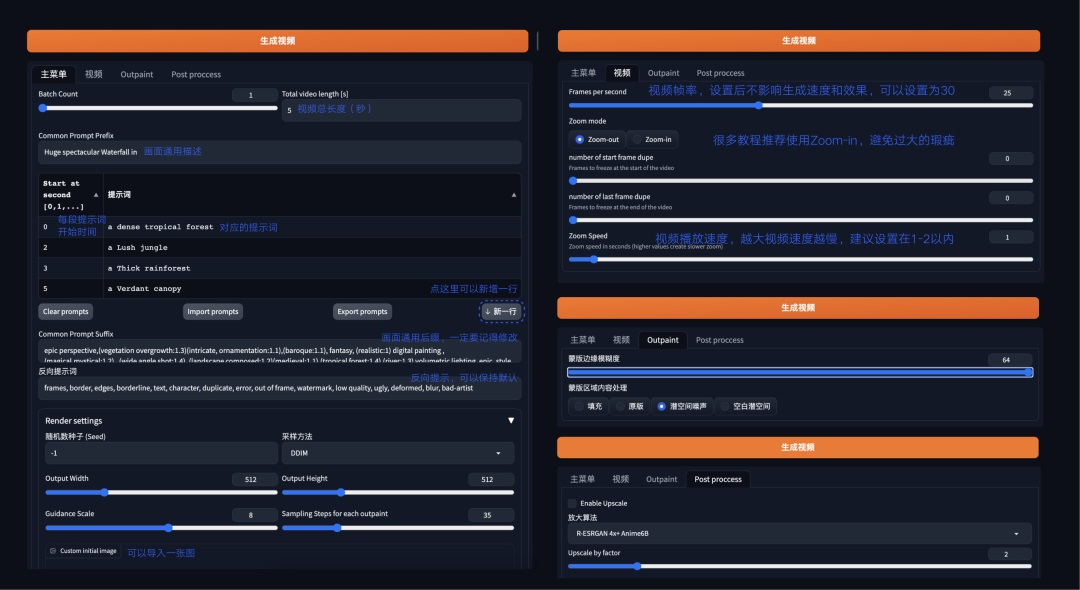
实践过程
实验了几次后发现,即使是蒙版边缘模糊度拉到最高,还是会出现图片之间明显的接缝,图片似乎会以叠加的方式融合,会出现一些内容被生硬盖住的情况。
详细的视频教学: https://www.youtube.com/watch?v=qkZXvQ5aMiYhttps://www.youtube.com/watch?v=E6ZYrzn5iWU&t=6s
E.AnimateDiff 文/图生视频
产品介绍

首先需要安装 SD 扩展并下载对应的运动模型。在 SD 的文生图 Tab 中可以找到 AnimateDiff 菜单,启用后,在生成图片的同时还会生成视频。9 月,AnimateDiff 也发布了相机运动控制模块,不过需要分别下载模型来实现。
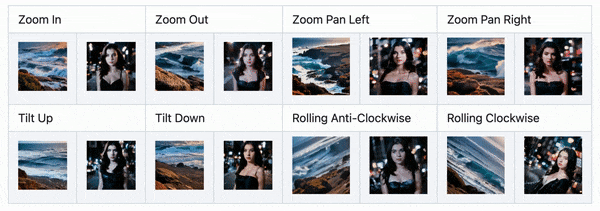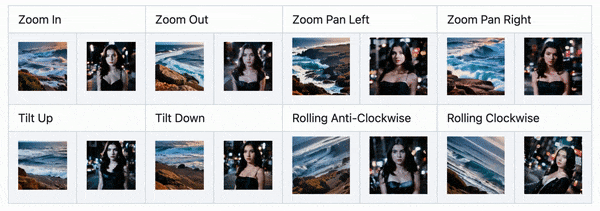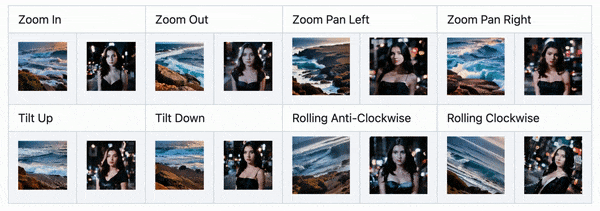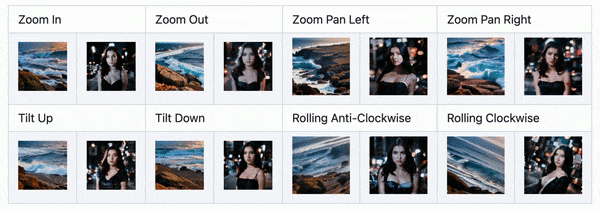
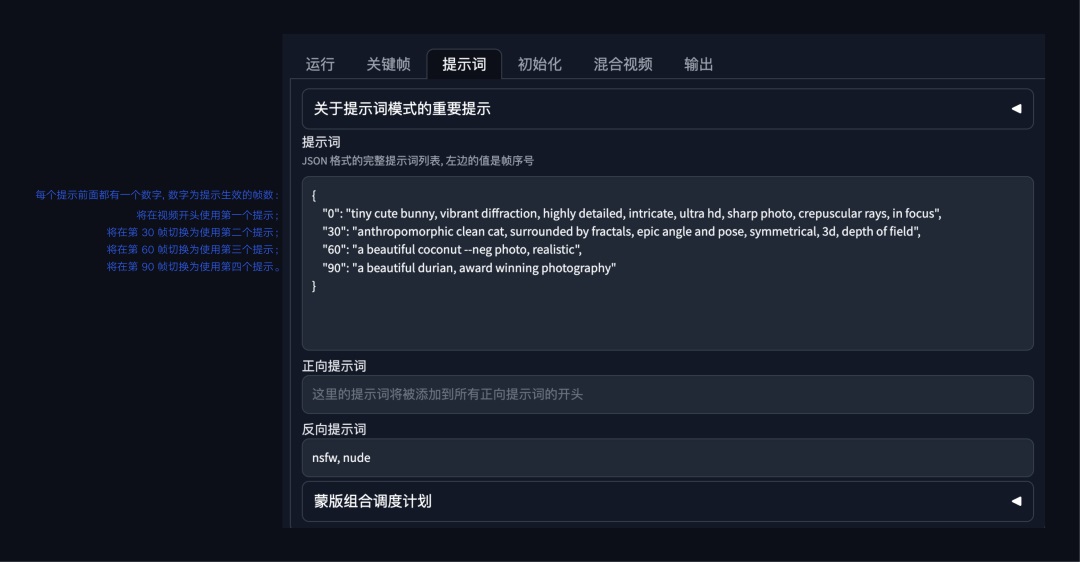
近期更新中,AnimateDiff 能够实现类似 Deforum、Infinite Zoom 中的分段提示词能力,直接在正向 Prompt 输入框中使用格式提示词即可实现。
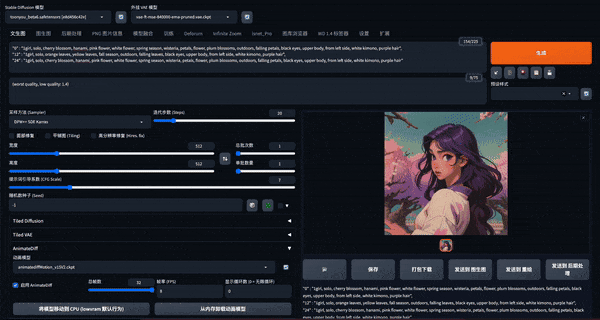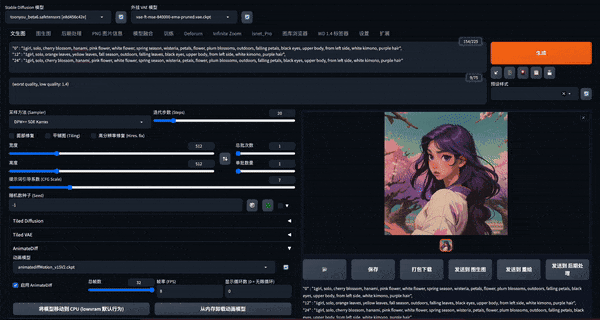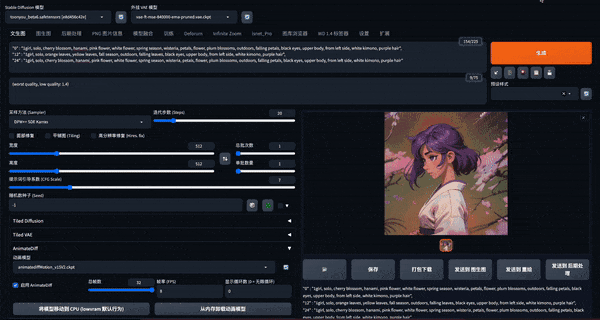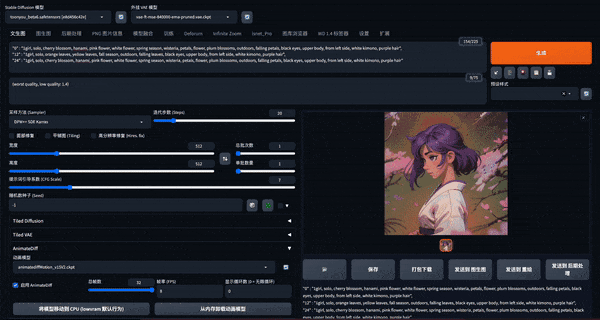
ComfyUI 是另一个基于 Stable Diffusion 的图形用户界面,可以通过拖拽图片的方式导入他人的工作流,部署也比 SD webui 更简单,生成速度快,缺点是节点控制比较复杂,深度学习有一定门槛。近期 ComfyUI 在 AnimateDiff 扩展的使用上受到欢迎。
超详细的 Stable Diffusion ComfyUI 基础教程(四):图生图流程
想一下,在我们使用 web UI 图生图的时候,他比文生图多了什么,是不是多了个加载图像的位置。
阅读文章 >
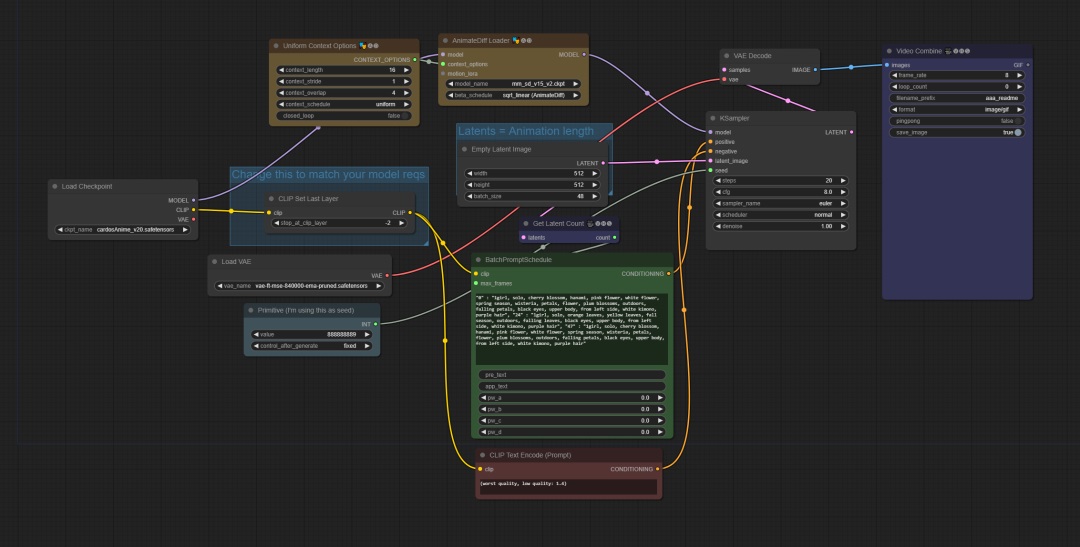
使用 ComfyUI+AnimateDiff 还能突破 webui 中 AnimateDiff 最高 32 帧的限制,在 Comfy UI 的 AnimateDiff 扩展 git 地址中,我们可以复用作者的工作流快速复现效果: https://github.com/Kosinkadink/ComfyUI-AnimateDiff-Evolved
资料推荐
Stable Diffusion webui 扩展地址: https://github.com/continue-revolution/sd-webui-animatediff.git
AnimateDiff Motion Modules 下载地址: https://civitai.com/models/108836Comfy
UI git: https://github.com/comfyanonymous/ComfyUI#manual-install-windows-linuxComfy
UI Mac 安装教程: https://stable-diffusion-art.com/how-to-install-comfyui/Comfy
UI Manager 安装、AnimateDiff 安装和初步使用: https://www.youtube.com/watch?v=SGivydaBj2w
F. Warpfusion 视频生视频
一款视频生视频工具,不过使用前需要购买该程序代码(10 刀),使用 Google Collab,webui 比较复杂。前段时间火爆全网的雕塑跳舞动画就是用该工具生成的。
详细教程和效果: https://www.youtube.com/watch?v=mVze7REhjCI
②Topaz Video AI
产品介绍
Topaz Labs 成立于 2008 年,总部位于美国犹他州,是一家图像处理软件公司。最初以 Photoshop 插件起家,后来转向研发独立软件。其于 2022 年推出 Topaz Video AI,能够提升视频清晰度、支持将视频升级到最高 60 帧的水平。Topaz 还提供了算法模型用于减少闪烁、去噪、去除动态模糊、颜色校正、慢动作等等。该产品可以作为 Pika labs、Runway、SD 视频生成扩展的最强辅助。价格为 299 美刀。
官方地址:https://www.topazlabs.com/topaz-video-ai
使用指南:https://docs.topazlabs.com/video-ai/features/user-interface
实践过程
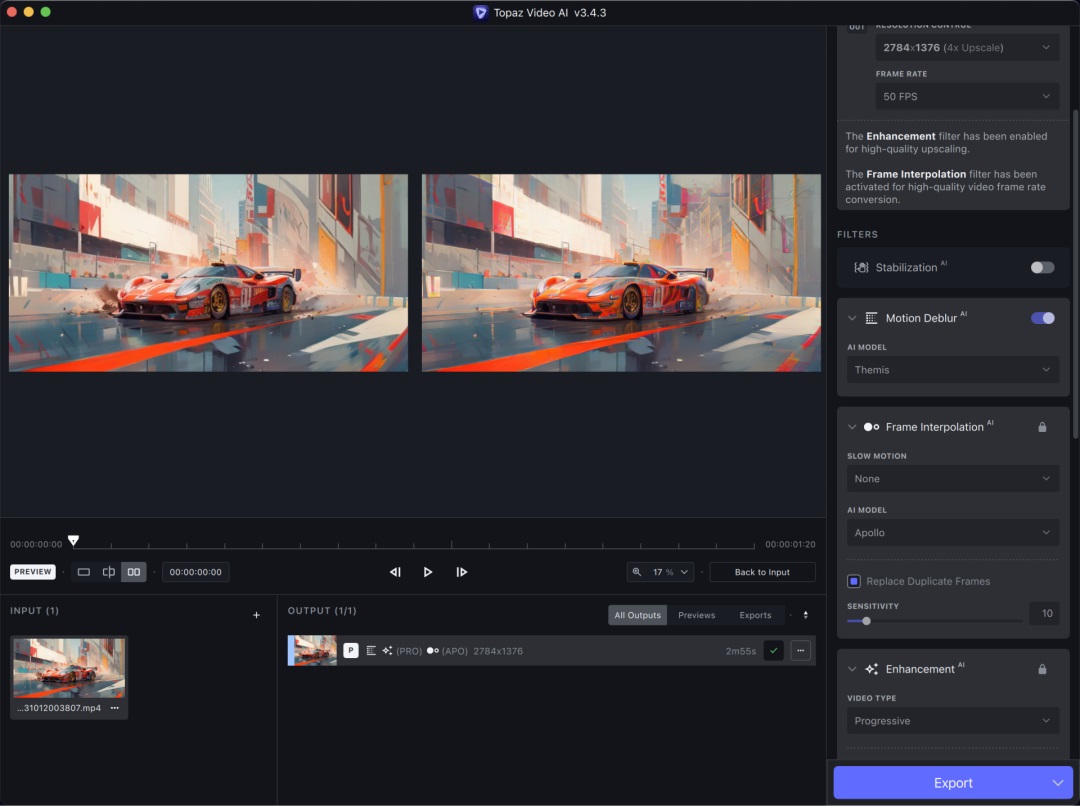
这里我将 Deforum 中的赛车图生视频拖入 Topaz 中进行生成,可以看到优化后闪烁问题有了极大改善,并且通过放大视频变得非常清晰。
视频上传后会有压缩,可能无法让大家感受直观的效果。
本小节产品多以网页、APP 形式呈现,个人用户可以很简单上手使用。该方向下目前体验上和 AI 能力上支持较好的属 Synthesia、HeyGen AI、D-ID 和 Opus Clip。前三者都是 AI Avatar+语音生成快速生产视频的产品。而 Move AI 则能够轻松实现动作捕捉。
1. Synthesia
①产品特点
强调无需麦克风、摄像机、专业演员出镜即可制作视频,内置 100 多种人物形象和多语言配音能力,帮助企业节省制作费用和周期。同时能一键生成多国语言视频,便于企业本土化推广。主打方向为:企业内部的网络培训课(通常需要一个人物形象出镜)、产品营销视频、客户服务(产品帮助文档转换为视频)等。该产品不提供免费方案,与 HeyGen AI、D-ID 对比更致力于服务企业客户。付费方案类似 MJ 的流量策略。官方透露的数据为 5w 用户、1500w 视频生成量。官网地址: https://www.synthesia.io/
②功能介绍
可以通过简单的 PPT 制作生成视频 Demo,可以替换 AI 头像库中的形象、制作简单的动画等。同时支持多种视频(PPT)模板。
2. HeyGen AI(原 Movio)
①产品特点
2020 年成立,和 Sythesia 类似。主打广告营销、企业培训、讲解、销售等多个需要人物形象出镜的内容。因为更面向 ToC 消费者,HeyGen 比起 Sythesia 能够体验到更多丰富的功能(需付费使用)。官网地址: https://www.heygen.com/
数字人制作神器 HeyGen 实测 !听说能让视频制作效率提升10倍?
大家好,这里是和你们一起探索 AI 的花生,今天我要来和大家聊聊数字人制作神器HeyGen。
阅读文章 >
By:Poonam Soni
②功能介绍
内置 100+ AI avatars,支持 40 多种语言,300+ 声音,除了语音生成和对口型,这部分内容更偏模版生成。此外还可以创建个人 Avatar,需录制两段 5-10 分钟的视频后生成。
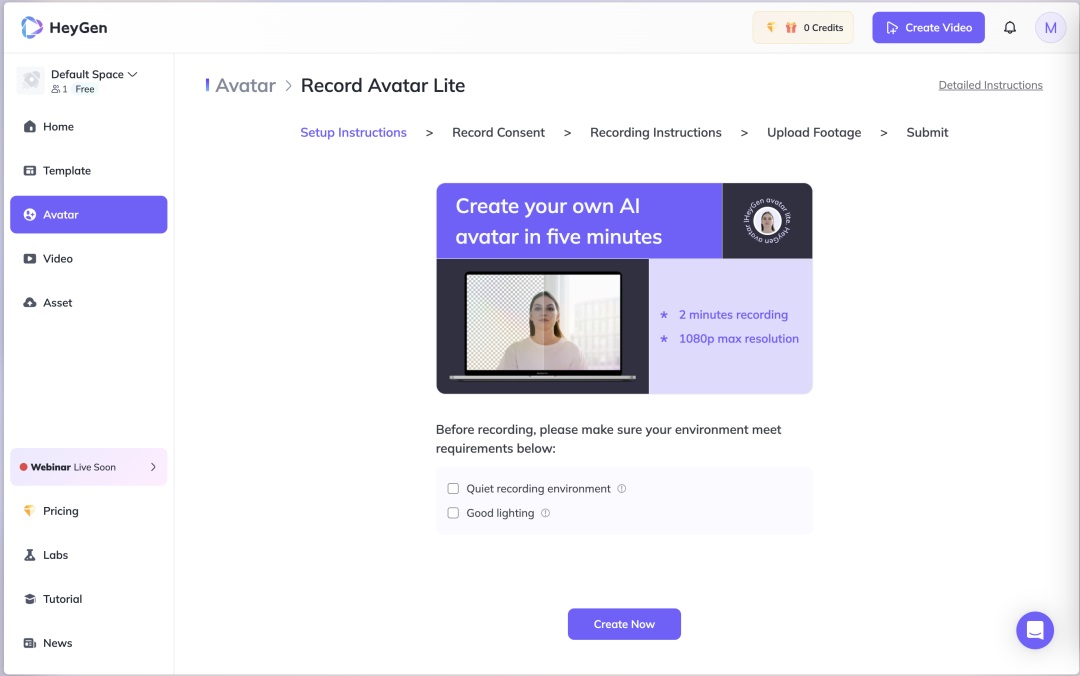
支持输入脚本快速创建视频。
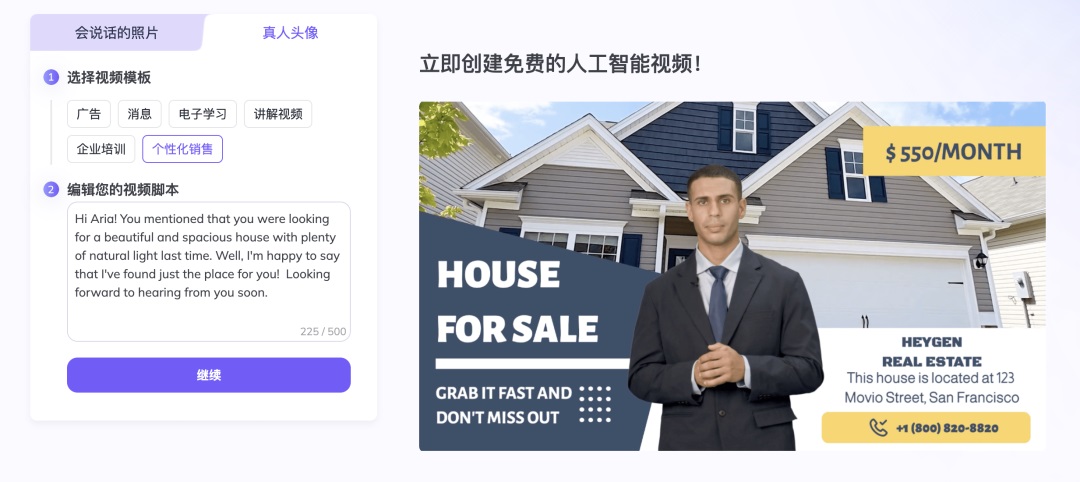
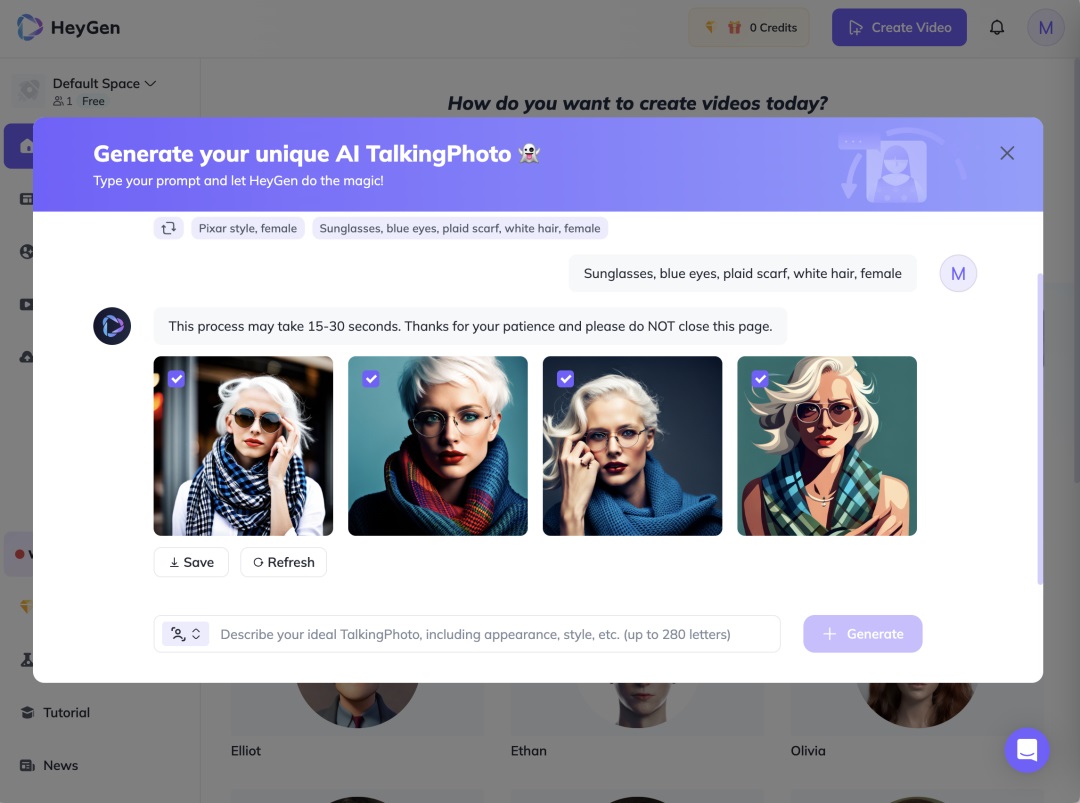
支持通过 prompt 的方式创建 AI Talking Photo(Avatar),并支持给 Avatar 更换服装、一键换脸。
最近推出的新功能 Video Translate 可以将视频中的语言翻译成其他语言,并保证嘴型和内容进行对应,该功能非常有助于企业在海外不同国家进行产品营销。(可以在左下角 Labs-Video Translate 找到)
3. D-ID
①产品特点
D-ID 来自一家以色列 AI 创业公司,该公司此前推出的“Deep Nostalgia”(将老照片中失散已久的亲人的脸动画化)和“LiveStory”(在动画照片中添加音频,让照片中的人讲述自己的生活史)等项目曾在 Tiktok 等社交媒体上疯传。D-ID 主打方向同样是 AI Avatar 生成视频,比起 Synthesia、HeyGen AI、D- ID 提供了更多 credits(20 个)让用户试用。除了 AI 视频生成器之外,该公司还提供与 Microsoft PowerPoint 兼容的 AI Presenters,允许用户将虚拟演示者添加到幻灯片中并创建更具吸引力和互动性的演示文稿。
D-ID !数字人视频制作神器,只需5分钟让照片开口说话
大家好,这是和你们聊设计的花生~ 大家最近在 B 站、抖音等各大视频平台上有没有看到一种新的视频类型——数字人视频,即视频中为出镜大家介绍内容的并不是真人,而是由 AI 生成的虚拟人物,人物说的话也是由 AI 配音的。
阅读文章 >
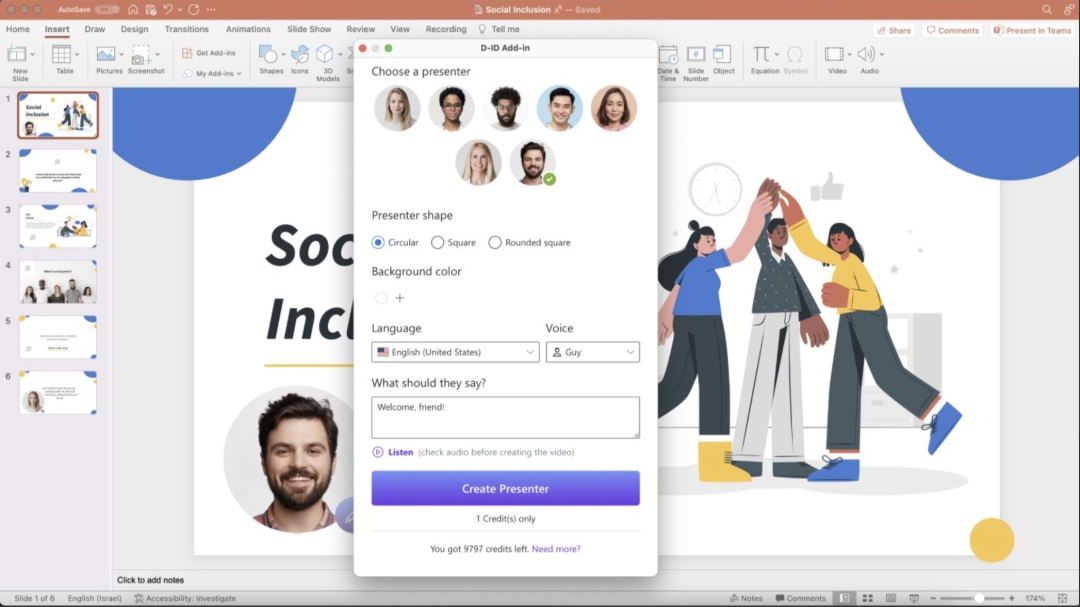
但实际测试效果远不如 HeyGen 自然,嘴部模糊较多。
官网地址: https://app.heygen.com
4. Invideo AI 脚本生成+视频匹配
①产品特点
该产品能够在数十秒时间内轻松实现 Prompt 转视频,并且支持通过编辑器进行后期更改。过去类似科技、财经、资讯类重脚本内容的视频在制作时需花费大量时间寻找视频素材、还需注意视频版权问题。未来可以使用 Invideo AI 类的产品快速、低成本地进行视频画面制作。
官网地址: https://ai.invideo.io
②功能介绍
在官方教程中,建议对视频平台、主旨内容、视频长度、语气、脚本风格进行描述
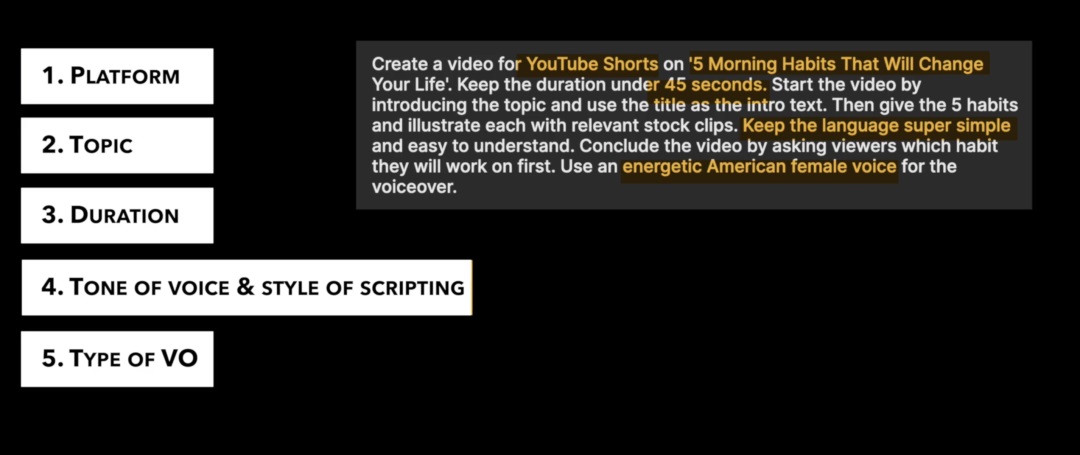
上传视频后,还会再次询问视频内容倾向
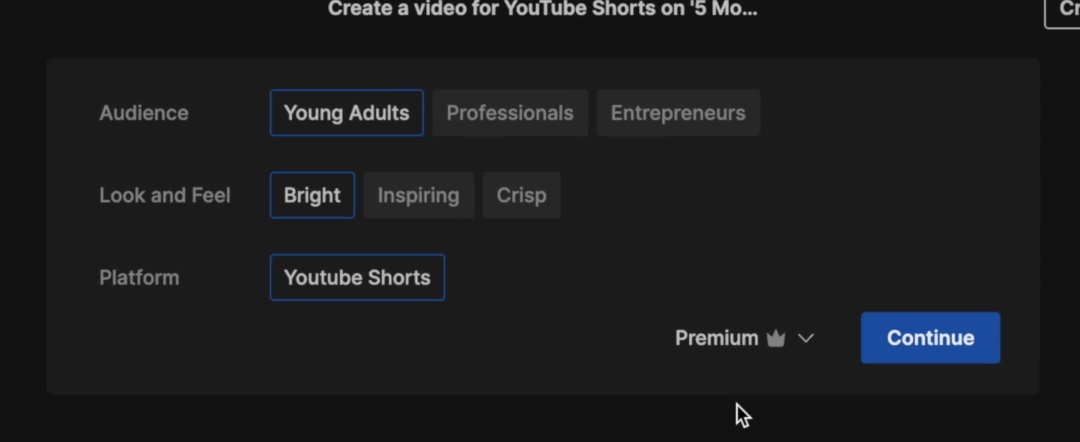
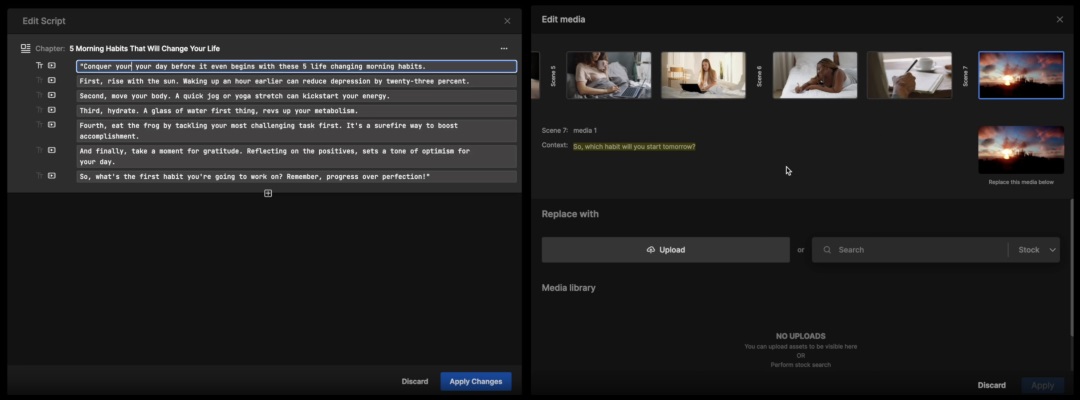
如果对生成的视频不满意,可以重新选择内容倾向进行编辑,也可以修改脚本、搜索并替换视频片段(由此可以看出区别于 Pika labs、Runway 的 AI 生成视频,Invideo 的原理是 AI 生成脚本并匹配视频素材)
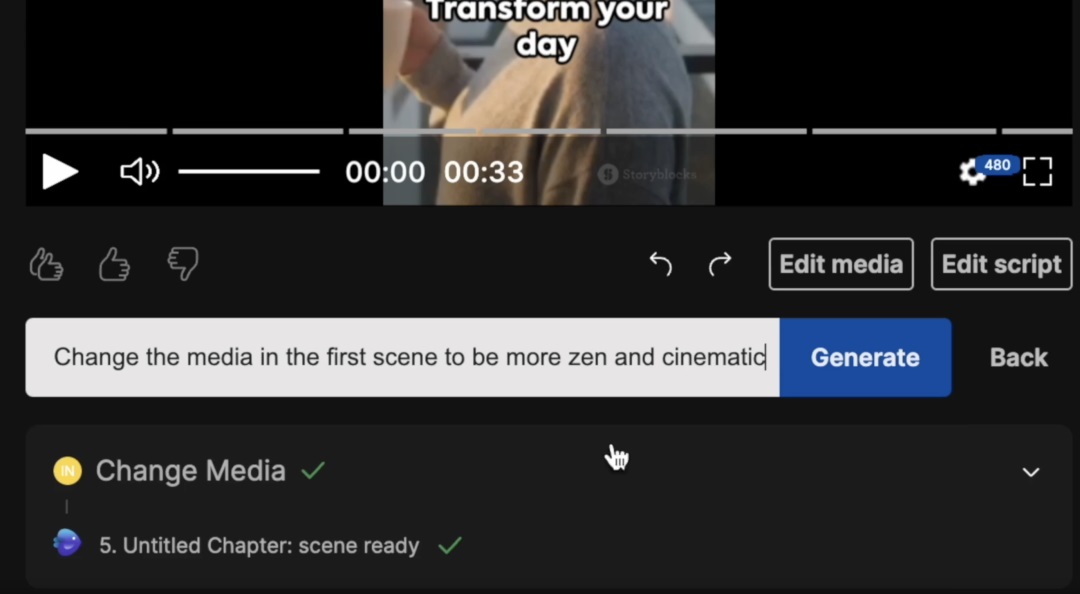
在视频生成后,仍可以通过 Prompt 修改视频内容,免费账户无法去除视频上的水印。
②实践案例
- 输入 Prompt“K 公司刚研制出了一款新品乳液,采用了天然草本精华,使用后肤色洁白透亮,并且不再担心冬天气候干燥带来的皮皮肤干裂困扰,请帮这款新品制作一个 30s 的宣传片”
- 选择 Youtube 平台非常快速地生成了该视频,标题为“Embrace Winter with K’s Herbal Emulsion 用 K’s 草本乳液拥抱冬天”,实际视频为 27s。
Opus Clip 长视频转短视频
②产品特点
支持上传长视频地址,自动将长视频转换为适合不同平台的短视频,支持自动生成字幕、符号表情、调整视频大小、并且能够自动识别人物主体,适合播客、长视频作者、营销人员使用。在多种视频内容和平台并存的流媒体时代,该工具很好的切中了创作者痛点。上线短短 3 个月便拥有了 40 万+用户,生成 3000 万+个剪辑。
官网地址: https://www.opus.pro/#ai-emoji-generator
生成多段视频后,系统还会给出评分分析该视频的传播能力。
今年早些时候,官方更新了算法,保证人物主体可以保持在屏幕中间。
有些遗憾的是,该产品无法在国内使用,并且检测到使用魔法后将取消账号获得的免费 credits,感兴趣的朋友可以付费使用。
5. Wonder Dynamics AI 动捕
①产品特点
发力 CG 场景,支持自动将 CG 角色动画、打光合成到真实场景中。使用流程主要为:自动识别视频中的人物动作,用户可选择扣除或者替换成 CG 形象,CG 形象会直接替换视频中的所有场景,节约了大量的逐帧 VEX(视频编辑和合成)工作。目前普通用户仅支持试用官网模板,官方提供的 CG 形象都偏科幻类、动画题材。
②官方案例
官方 Twitter: https://twitter.com/DemNiko1/status/1683932450907652096
官方网站 : https://wonderdynamics.com/#features
6. Move AI AI 动捕
由一家成立于 19 年的英国公司推出,该产品主打通过手机拍摄视频画面实现动作捕捉,无需佩戴动捕设备即可获取动作捕捉数据,能够极大降低 3D 动画制作成本。
(目前测试版应用还比较简陋,公开可下载的 Move AI 版本目前也不再接受新用户注册,全部功能开放使用应该还需要一定时间)
官网地址: https://www.move.ai/
①使用方法
Move AI 支持多台移动端设备同时录制视频,视频上传到 web 端后进行动作检测,支持导出为 FBX 等格式的文件,并导入 iClone 8、Blend、Maya 等软件中,驱动模型进行动作播放。
目前无法实践测试效果,找了半年前的一个测评案例给大家看下,by JSFILMZ: https://www.youtube.com/watch?v=PDFqN_pvEUE
该产品若开放使用,会对电影、游戏 3D 动画制作、虚拟主播直播、影视剧制作等场景会产生深刻影响。Move AI 强调和其他动捕使用手机拍摄短片,这也让我看到了在游戏和产品设计工作中大幅降低 3D 动画制作成本的可能。未来设计师可能只需要拍摄特定动作并映射到制作好的 3D 模型中,快速制作动画方案。
本小节产品无法被个人用户使用,仅开放给企业客户。
1. Deep Motion
Deep motion 开发了端到端的人体动态捕捉系统 LiveMotion。它可以只通过一个摄像头就可以精确捕捉人的全身动作,无需佩戴任何传感器设备。其核心技术是他们自主研发的基于深度学习的人体姿态估计和动作预测算法。该算法可以从单个视角准确构建和预测人体的三维动作。目前 Deep Motion 在探索与一些头部科技公司的合作,以将其人体动态捕捉技术应用到更多消费级产品中。在官网上传一段 20s 以内的视频,便可以选择形象创建动态捕捉后的 Avatar 动画,支持用户自定义 Avatar 形象。
用 Deep Motion 识别了一段跳舞视频
Deep Motion 做为动捕领域老牌选手,致力于精确再现人体动作进行专业内容制作。而 Move AI 致力于使用移动端低成本拍摄,产品体验更简单,使用门槛更低。
2. Stability Animation
Stability AI 在 2023 年初发布,支持视频+文本生视频(Video 2 Video)、图片+文本生视频、文本生视频但目前仅支持以 API 的方式接入,收费较高。
产品介绍: https://platform.stability.ai/docs/features/animation
本小节挑选出一些还不具备完整产品形态,或仅提供少数功能测试而没有将全部能力开放使用。但从产品方向、目前披露的实验效果来看值得持续关注的项目。
1. Rerender A Video
该项目由南洋理工大学团队发布,是目前为数不多的专注于视频增强和修复的 AI 项目之一,代表了通过深度学习提升旧视频质量的新方向。项目核心特点在于重新渲染用户输入的视频时能够提升视频在帧之间的时间一致性。该团队将 Rerender a Video 和之前的几类文生视频框架进行了对比,包括 FateZero、vid2vid-zero、Pxi2Video 和 Text2Video-Zero 等,Rerender 效果提升显著。该项目目前已开源,可在 Hugging Face 免费试用。
项目介绍: https://anonymous-31415926.github.io
Demo 地址: https://huggingface.co/spaces/Anonymous-sub/Rerender
①如何使用
上传视频后,可以调节相关数值并进行进行几个关键操作,解析见图片:
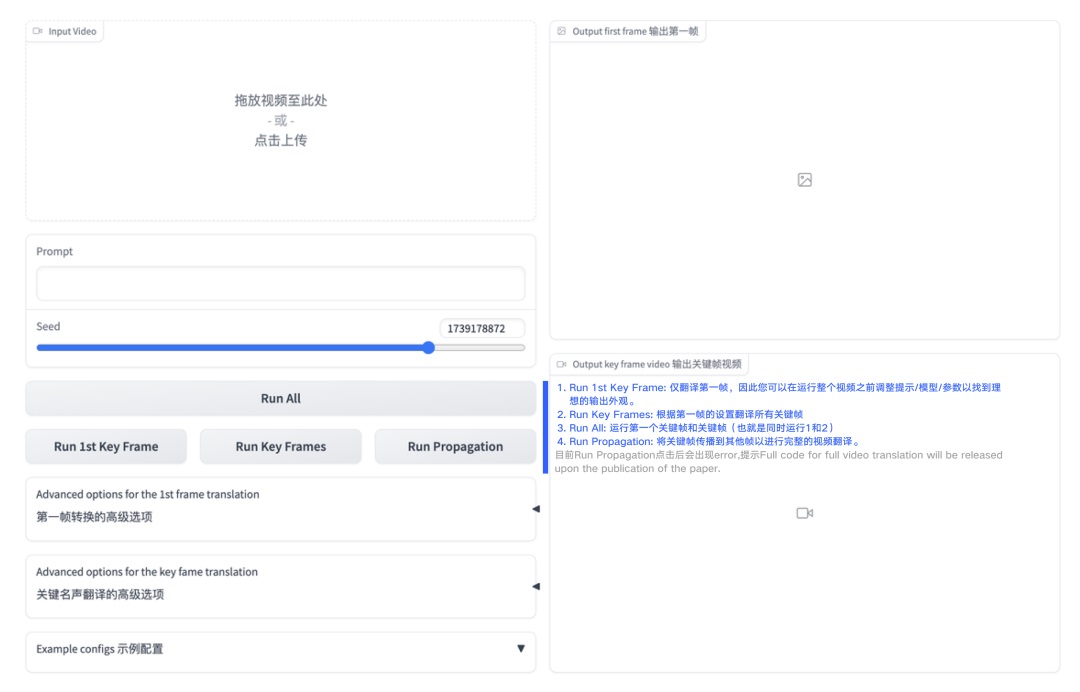
在 T4 GPU 下,大小为 512×640 的视频每个关键帧的运行时间约为 1 分钟。总体生成效果好,但速度较慢。
3. Showrunner AI
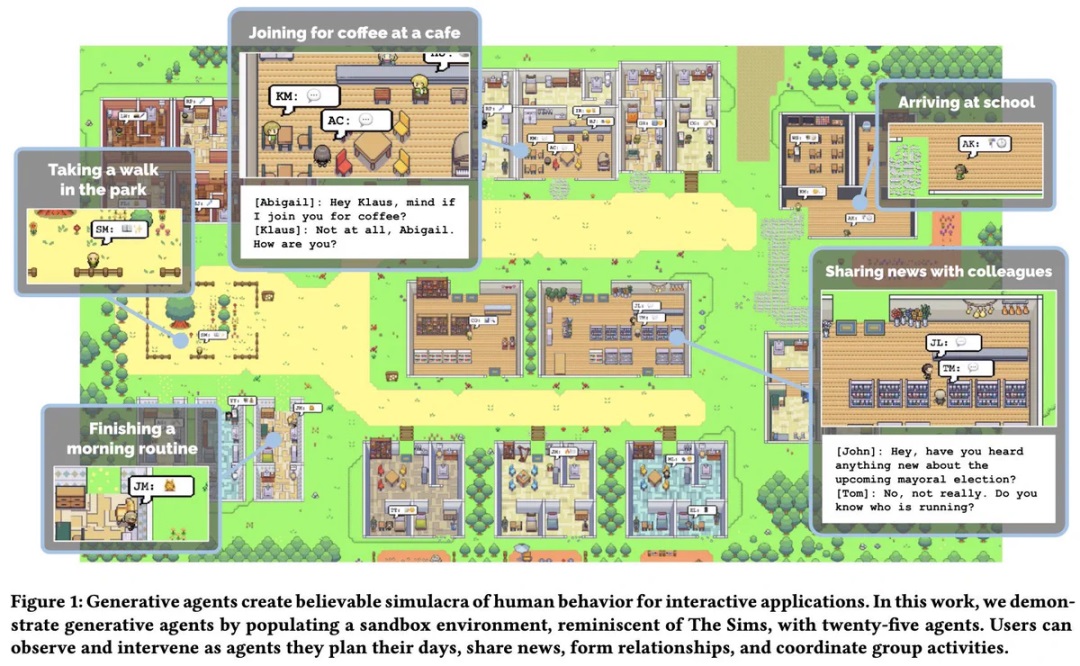
早在今年 4 月,斯坦福大学和 Google 合作开发的有关 AI 数字世界的的研究 SmallVille(小镇) 就引起了 AI 领域的广泛关注,25 个人工智能体居住在一个沙盒虚拟城镇中通过复杂的社交互动来执行他们的日常生活。(该项目近期已开源)
①项目介绍
而 Showrunner AI 项目受到 SmallVille 项目启发,致力于采用多智能体和 LLM 大语言模型模拟生成的故事情节内容。主要运用 LLM、Diffusion model 和 IP 形象生成高质量情节内容。在剧集生成过程中,故事系统可以利用模拟数据(一天中的时间、区域、角色)作为提示链的一部分自动生成场景,提示链首先生成合适的标题,第二步生成场景的对话。剧集系统则负责为每个场景生成角色。场景中定义了每个演员的位置、对话。每个角色的声音都已提前克隆,在对话生成后能够生成语音文件。
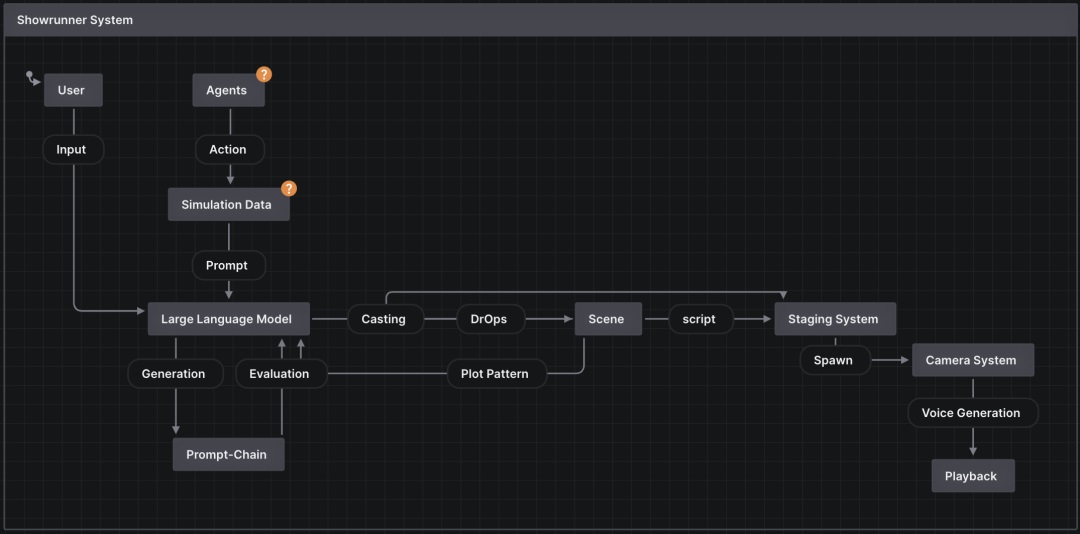
目前只有官方视频流出,视频中用户只需选择南方公园的角色撰写一个新的故事,并且生成新的电视节目剧集:
②可能的应用场景
剧情粉丝可以将个人角色融入到故事其中创作新剧集,甚至创作和原著完全不同的剧情走向。
创作者可创作个人 IP 和故事,制作相应的角色创作剧集并开设相应的付费频道进行盈利。比如小说创作者可以更轻松的将小说剧情转电视剧或者动画。
官方 twitter: https://twitter.com/fablesimulation/status/1681352904152850437
论文地址 : https://fablestudio.github.io/showrunner-agents/
内测申请: https://www.thesimulation.co/
③推荐关注
推荐一些在 AI 绘画、动画制作领域的头部创作者
- Pika labs、Runway、Deforum 的官方号,除了及时更新新功能消息,还会转发使用产品创作出的优秀动画效果。
- 在 Runway Studios 中,可以查看更多创意合作案例: https://studios.runwayml.com/#after-light
- 一位喜欢用 Pika labs 制作广告的导演,他的视频质量非常高: https://twitter.com/MatanCohenGrumi
- Ammaar Reshi,其个人网站记录了所有 AI 作品 https://ammaar.me/ai, 其团队使用 Stable WarpFusion + Davinci Resolve 制作完整的动漫剧情,制作过程分享
- 使用 Runway 制作烟雾效果的思路: https://twitter.com/CitizenPlain/status/1687147807499792384
- Ricardo Villavicencio 使用 Runway 进行短篇动画制作的过程分享:https://twitter.com/runwaymlstudios/status/1692163312207745074
- @valleeduhamel 使用现有的素材、Gen-1 和大量合成创作了新电影《After Light》的过程分享: https://twitter.com/runwayml/status/1679484350641983491
- 国内视频头部创作者: 海辛、莱森
当前 AI 视频生成领域仍面临生成质量不稳定导致的不同帧之间的“闪烁”现象,以及动作扭曲不连贯、细节表征不足等技术难题。并且 AI 视频当前还远没有达到简单、便捷,可控性增强的同时,上手成本也在成倍增加。未来的研究突破方向包括:生成更长时序、更高质量的视频;渲染复杂的三维虚拟背景;模仿细微的人类运动和肢体语言;以及实现超高分辨率视频生成等。随着 AI 能力的增强,AI 视频生成技术、可交互性还拥有很大的进步空间。
参考链接
- 关于视频的 AI,现在都有什么? https://www.notion.so/AI-f34125f586c44a1194ae5b2a0b64c4ea
- 和 AI 一起做动画 | 将人工智能融入动画工作流的案例和实践经验 https://mp.weixin.qq.com/s/tGlvrC_CanprU7eTooqShg
- 2023 年利用 Ai 根据文本生成视频技术发展到什么程度了? – 微软亚洲研究院的回答 – 知乎 https://www.zhihu.com/question/585003769/answer/2971702509
- Stable Diffusion 喂饭级教学:B 站 nenly
评论前必须登录!
注册